
AWS Lambda is an awesome offering. You provide the code, and AWS handles the infrastructure and execution for you.
But where is your code actually executed? How does AWS do it?
I recently tried to find it out for myself, and this article is the result of what I learned.
Table of Contents
Open Table of Contents
Thinking about Lambda
We know that we can write a script that looks like below, and then upload it to AWS while they take care of everything else. And from simply looking at the code, it doesn’t look like the usual API method we’d implement in Express.
exports.handler = async (event) => { return { statusCode: 200, body: JSON.stringify({ msg: "Hello from Lambda!" }) };};We’re exporting a function, so something else must take our code, import it, and then handle everything else.
Conclusion number one: Something must run our code.
We also know the infamous cold start issues which became better over time but are still there. Sometimes the environment is shut down and then started again.
Conclusion number two: Whatever runs our code can be shut down and started again.
Have you ever noticed that it’s actually impossible to access anything on the host system? If not, try to, and you’ll see that the environment will prevent it.
Conclusion number three: The environment is pretty secure.
Thinking about the technology Lambda is based on
There are a few ways of how AWS could have implemented Lambda (taking into account its initial release year of 2014):
- Containerization
- Virtualization
- Something running on bare metal
We can quickly rule out “Something running on bare metal”. AWS already had EC2 at that time and some good knowledge of virtualization. It would not have made a lot of sense for AWS to step back from virtualization and not make use of their existing infrastructure. They basically had everything in place to provision a virtual machine on-the-fly.
What about Containers then? They can be spun up quickly and disposed of again. AWS could have taken the code, wrap it with something and then put it inside a container. This would have been a great idea, but also something completely new for AWS at that time. Additionally, it would not explain the (old) cold start issues, because containers are usually pretty fast to spin up.
What about virtualization then? It would make a lot of sense. At the time of starting Lambda, AWS already had EC2 and all the infrastructure to provision a virtual machine on-the-fly. It would also explain why a lambda function being cold-started could sometimes take so long until it finally served a request. But how did they manage to reduce the cold start time up to today?
Before we dive deeper, I’ll give you the answer: Lambda has, since its release, been based on virtualization technology. No fancy containers, nothing self-developed.
It simply made the most sense for AWS to do it exactly this way. They had all the knowledge, as you’ve read above, and they had the infrastructure for provision. All they had to add was something to wrap user functions, and something to call them, as well as some supporting services which could handle eventing.
And now that we know that it’s virtualization, we can take a look at what’s exactly used nowadays.
Enter Firecracker
Firecracker is a virtualization technology, or better, a virtual machine monitor (VMM) developed at Amazon (now open-sourced) and written in Rust.
It’s the engine powering all your Lambda functions.
What Firecracker basically does is creating and managing a multitude of Linux Kernel-based Virtual Machines (KVMs), which are microVMs that are faster and more secure than traditional VMs.
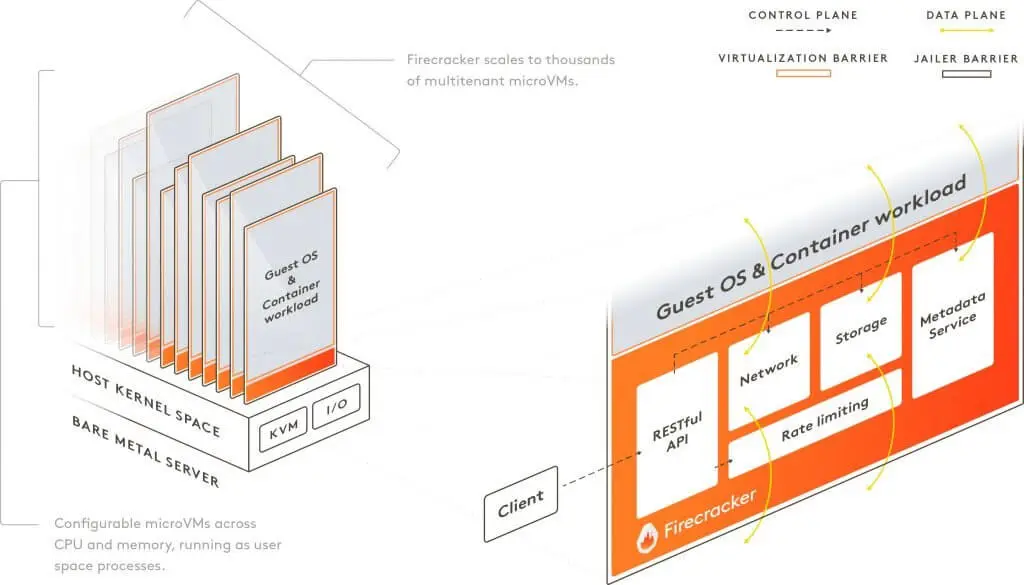
The interesting thing about those microVMs is, that they are actually on par with containers regarding memory footprint and start-up time, all while offering even more security due to the advanced features KVM offers.
You can read more about KVM here.
Firecracker comes with a REST API that is used to create VMs, delete them, manage them, etc. Whenever you create a new lambda function and upload your code, the Firecracker REST-API is called under the hood to create a microVM with your function’s CPU and memory settings.
AWS keeps base images that contain language/runtime-specific bootstrap code. This is the code that actually invokes your handler, passes it the request, and takes the response to return it to the caller. This is also the code where various metrics are measured that are then used to calculate your bill.
You can imagine the code as containing an infinite loop, waiting for requests, passing them to your function, returning the response, and gathering execution metrics.
After Firecracker creates a new microVM, including your language-specific runtime, your code is then put into its /var/runtime/bin folder. This is the place where the bootstrap code resides, too. Now your function is basically able to run and accept requests.
AWS will, after a while, however, shut the VM down to save resources on their side. This is, once again, a call to the Firecracker API.
Incoming requests, e.g. through API Gateway, lead to Firecracker being tasked to start the VM again, such that it can process the request.
Surrounding infrastructure and supporting services
There are of course a lot of surrounding systems and services which do their work to make AWS Lambda what it is.
There are services and systems around Firecracker that make all those requests to its API. Some services are routing the requests. Some services decide when to call Firecracker to shut a certain VM down or pause it, and when to spin it up again. And there are certainly a lot more services, like Queues, scheduling asynchronous messages, and much more.
Conclusion
It’s pretty interesting to see what way AWS has made Lambda what it is today, and even more interesting to see Firecracker and how it solves many problems serverless functions cause for service providers. Firecracker is an integral part of it, as a pretty exciting piece of technology that doesn’t go the usual container route but uses another awesome feature of the Linux kernel: KVM.